1. MongoDB란?

MongoDB는 *NoSQL의 데이터베이스이며 관계형 데이터베이스 구조로 사용하는 오픈 소스 소프트웨어이다. 따라서 다양한 언어로 파일 저장소 기능은 물론 강력한 쿼리 기능을 가진다.
*NoSQL은 틀이 짜여있지 않고 한줄 한 줄 도큐먼트로 사용하며 비정형화 데이터이다.
장점: 데이터를 유연하게 데이터를 사용가능
2. Robo 3T란?

MomgoDB에 저장된 데이터들은 보다 보기 쉽게 시각화해주는 GUI 프로그램이다.
3. 프로그램 다운로드
1) MongoDB 다운로드 링크
www.mongodb.com/try/download/community
MongoDB Community Download
Download the Community version of MongoDB's non-relational database server from MongoDB's download center.
www.mongodb.com
2) Robo 3T 다운로드 링크
Robomongo
Robo 3T: Simple GUI for beginners Robo 3T 1.4 brings support for MongoDB 4.2, a mongo shell upgrade from 4.0 to 4.2, the ability to manually specify visible databases, and many other fixes and improvements. View the full blog post. Download Robo 3T
robomongo.org

*Studio가 아닌 오른쪽 simple GUI로 진행하겠습니다.
4. MogoDB에 데이터 저장하기
저번에 포스팅했던 네이버 데이터랩 실시간 검색순위를 크롤링 한 데이터를 MogoDB에 저장해 보겠습니다.
네이버 실시간검색 순위 크롤링 링크:
파이썬으로 네이버 실시간검색 순위 클롤링(crawling) 하기
1. 우선 크롤링을 위하여 pip install bs4를 터미널 창에 입력하여 bs4패키지를 다운로드합니다. 2. 크롤링을 위한 코드 입력 import requests from bs4 import BeautifulSoup headers = {'User-Agent':'Mozilla/..
for-it-study.tistory.com
1) 먼저 Python에서 MonggoDB를 사용하기 위하여 pymongo pakge를 다운로드합니다.
cmd창에 해당 명령어 입력
pip install pymongo2) 그 후 pymon를 import 하고 MongoDB와 연결
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsearch # MongoDB에 dbserch라는 이름으로 연결 후 db라는 변수로 선언(MongoDB는 27017의 호스트 번호를 사용한다고 합니다.)
db = client.dbsearch에서 dbsearch는 저장되는 데이터베이스의 이름이므로 원하는 이름으로 변경 가능합니다.
3) MongoDB연결 확인 및 Robo 3T와 연결하기
- 다운로드한 Robo 3T를 실행하면 다음과 같은 윈도 창이 나옵니다. Create 클릭
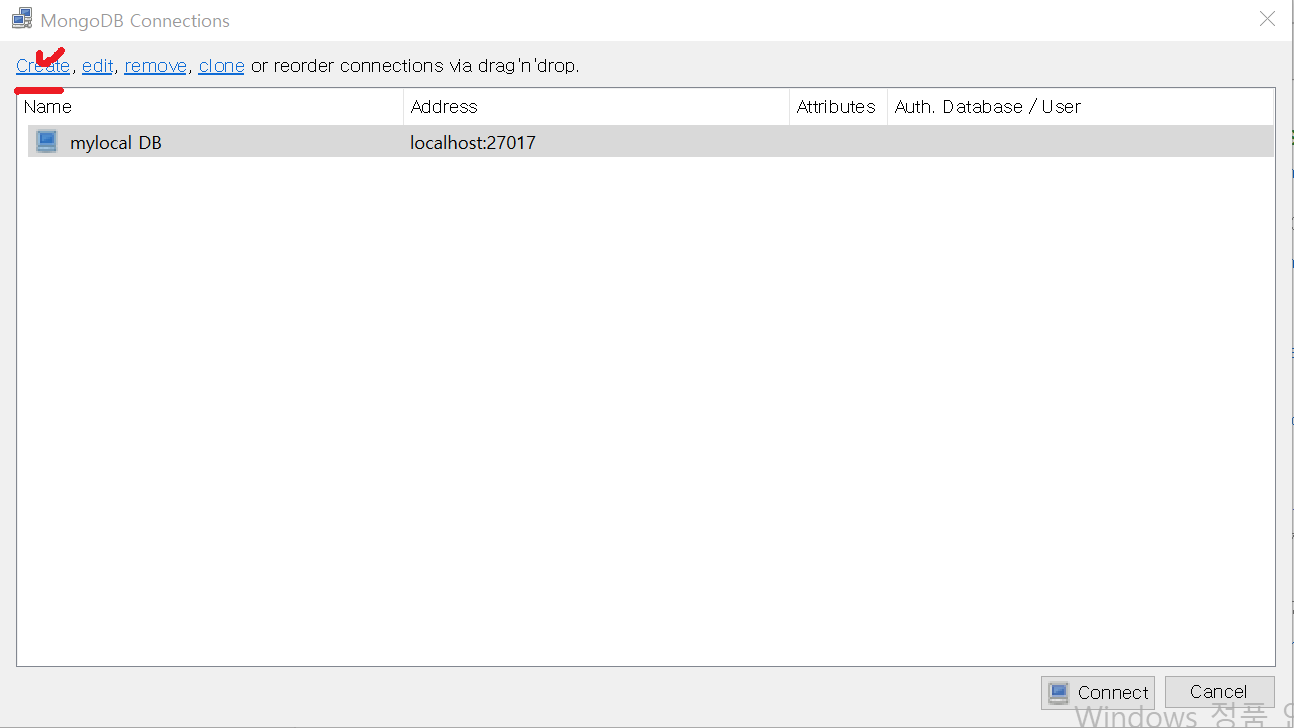
- 원하는 DB의 이름을 설정해주고 SAVE 해줍니다. (필자는 mylocal DB로 설정)

4) 전체 코드 및 설명
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsearch # MongoDB에 dbserch라는 이름으로 연결 후 db라는 변수로 선언
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'}
url = 'https://datalab.naver.com/keyword/realtimeList.naver?where=main'
res = requests.get(url, headers = headers)
soup = BeautifulSoup(res.content, 'html.parser')
data = soup.select('span.item_title')
i = 1
for item in data:
rank = str(i)+ "위 :" # 순위를 나타내기 위한 함수
i = i+1 # 순위를 data수만큼 1씩 추가하기 위한 함수
title = item.get_text() # 실시간 검색어를 text로 가져오고 title로 선언
doc = {
'rank': rank,
'title': title,
} # MongoDB에 저장하기 위하여 dictionary 타입으로 저장
db.search_rank.insert_one(doc)중간의 bs4를 임포트 하는 코드부터는 위의 링크에서 복사하시면 됩니다.
추가로 네이버 데이터랩에서 가져온 실시간 검색 순위를 doc이라는 변수에 dictionary형태로 저장합니다.
doc = {
'rank': rank,
'title': title,
}
rank는 순위, title은 검색어 제목입니다.
또한 마지막 줄의 db.search_rank.insert_one(doc)는 MongoDB를 연결했던 db라는 변수에 search_rank라는 이름으로 doc이라는 이름의 dictionary를 저장하겠다 라는 뜻입니다.
즉, 뒤의. insert_one()은 MongoDB에 데이터를 저장하는 명령어입니다.
4) 결과


다음과 같이 MongoDB에 search_rank라는 이름으로 데이터들이 잘 저장되었습니다.
'프로그래밍 > python' 카테고리의 다른 글
| Python 리스트(list)와 튜플(tuple) 개념 정리 (1) | 2024.01.26 |
|---|---|
| 파이썬(python) 프로그래머스 두 정수 사이의 합 구하기 (0) | 2020.10.24 |
| Python 백준 알고리즘 2753번 윤년, 2884 알람 문제풀기 (0) | 2020.09.07 |
| Python 백준 알고리즘 곱셈 문제 풀기 (0) | 2020.09.06 |
| Python 백준 알고리즘 문제 A+B 및 사칙연산 풀기(input,map,split) (0) | 2020.09.06 |